| A l'origine, le télégraphe utilisait un code de 5 bits. Cela permettait de transmettre des lettres (majuscules uniquement), des chiffres et quelques symboles. Mais il n'est pas possible de transmettre des codes spécifiques pour les machines de composition comme la linotype. Avec l'arrivée des ordinateurs, un code à 7 bits devient nécessaire pour transmettre plus de caractères spéciaux qui sont utilisés en programmation. Et finalement on passe à des mots de 8 bits. |
-
|
On est très limité dans le choix de caractères quand on ne dispose que de 5 bits. On peut coder le CR et LF uniquement en "lettres", ce qui libère deux caractères supplémentaires quand l'imprimante est en "symboles". Cette modification n'est pas reprise au standard et ne pouvait être utilisée qu'entre systèmes compatibles. Mais deux symboles supplémentaires, c'est encore trop peu...
Plus de bits: 6 bitsLa solution est d'utiliser plus de bits pour représenter un caractère. Ces systèmes ne sont pas standardisés. Un système qui est interessant est la linotype.Les premiers systèmes électroniques font leur apparition, ce qui élimine la limite mécanique des 5 bits.
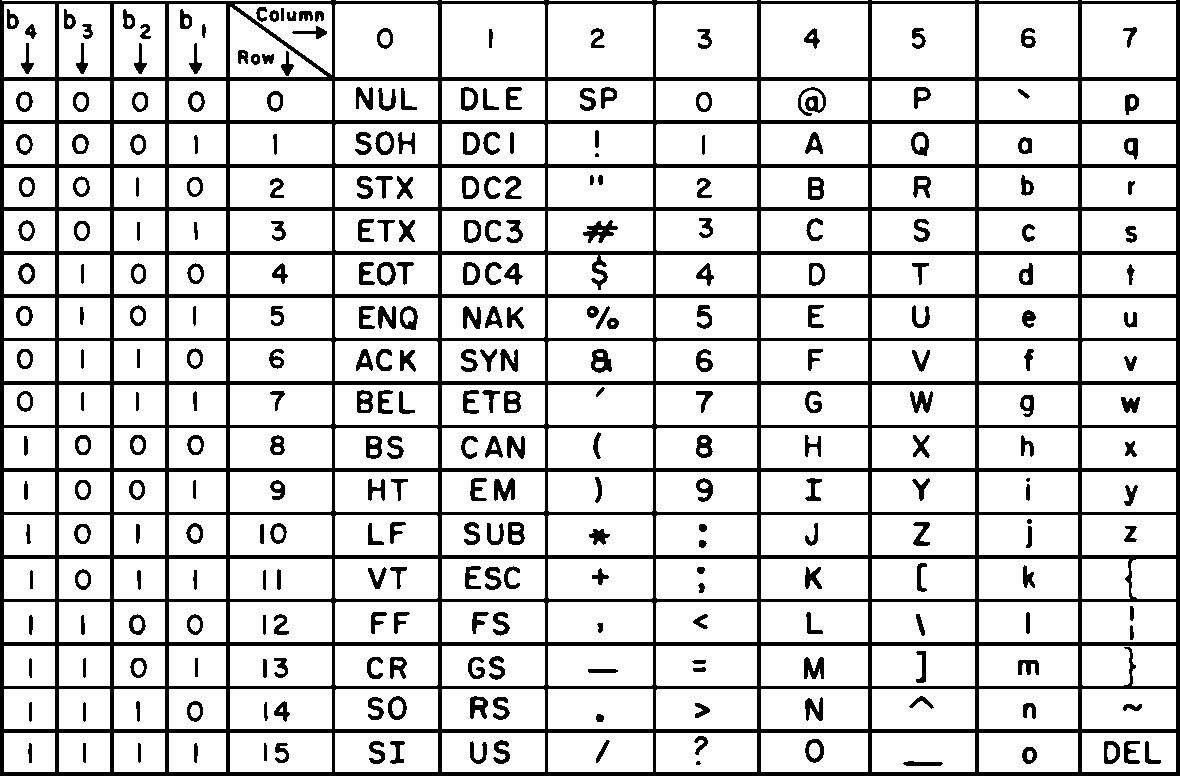
Et encore plus de bits bits: 7 bitsNous entrons lentement dans le monde moderne avec le code à 7 bhits le plus connu: le code ASCII (American Standard Code for Information Interchange) qui est toujours à la base des systèmes de codage modernes. Le code est utilisé par certaines télétypes électroniques. Le code à 7 bits pouvait représenter beraucoup plus de symboles que le code ITA-2: ; # < > ! [ ] { } & $ * \ _ |. Les languages de programmation comme FORTRAN et BASIC ont besoin de plus de symboles différents.
Dès l'origine on a tenté de limiter l'usage de la fonction shift, car une erreur de communication pendant l'envoi d'un shift peut rendre une grande partie du message illisible. Ce qui est par contre très important ce sont les codes DC1 et DC3 (device control). C'était à l'origine des codes génériques sans fonction spéciale, mais qui ont rapidement été utilisé pour le flow control, pour indiquer que la mémoire tampon du récepteur est pratiquement remplie. DC3 (ou <control>-S) est envoyé par le récepteur et l'émetteur doit alors immédiatement stopper l'envoi de nouveaux sysboles jusqu'à la réception d'un DC1. Ces codes ont reçu un autre nom, XOFF et XON (transmit off - vtransmit on). Dans la documentation, un symbole de controle est souvent indiqué avec un ^ comme (<control>-G) = BEL. La touche <CONTROL> de l'ordinateur permet de transmettre ces codes (valeur ascii - 64).
Certains condes sont encore d'application pour les applications basées sur le terminal comme l'application CMD de windows et le terminal de linux. Quand un listing défile, un code <control>-S bloque le défilement. FF (form feed) est utilisé par les imprimantes texte pour sauter à la page suivante ou pour vider l'écran d'ordinateur. Pour indiquer la fin d'un texte, on utilisait ^D (EOT: end of text). Ah, toute une époque... ISO 8859-1 est une des extensions du code ascii 7 bits qui est utilisée dans la plupart des pays européens. Quand tu regardes le code source de cette page, tu vois <meta charset='ISO-8859-1'>: la page est codée avec cette extension. En France on utilise plutot ISO 8859-15 qui permet le symbole œ que je code en utilisant une entité html œ. C'est pas grave, car mon clavier ne permet pas de saisir directement le symbole œ.
Et c'est pas fini: 8 bitsLes premiers ordinateurs personnels arrivent sur le marcvhé, et ils utilisent tous des mots de 8 bits. Le codage utilisé est toujours 7 bits ascii et les ordinateurs auraient pu travailler en ascii, mais c'est techniquement pas très pratique (calculs, adressage,...)Les 128 codes ascii ont été étendus avec des symboles graphiques ou des caractères propres à une langue. Quand on échange des fichiers binaires (programmes, images,...) il faut transmettre les 8 bits. Les modems sont conçus pour des mots de 8 bits. Les télétypes ont fait le saut de 5 à 8 bitys dès qu'ils sont devenus électroniques. Le telex était par exemple un système à 8 bits. Les télétypes étaient utilisés pour communiquer avec des ordinateurs avant l'arrivée des terminaux. La modulation du signal n'était pas nécessaire, car l'imprimante se trouvait à coté du mainframe et le signal ne devait pas être envoyé par ligne téléphonique. On utilisait une boucle de courant 20mA (au lieu de 60mA pour les télétypes mécaniques). Beaucoup de mainframes avaient une boucle de courant 20mA comme standard. On est passé lentement à la norme RS-232 qui était une norme définie par des tensions et non plus par des courants. |
Publicités - Reklame