|
Les paramètres SMART permettent de controler l'état physique d'un disque dur et donc de prévenir la perte de fichiers parce que le disque est défaillant. Mais tout comme chez les sportifs de haut niveau, personne ne peut prévenir une défaillance cardiaque brusque.
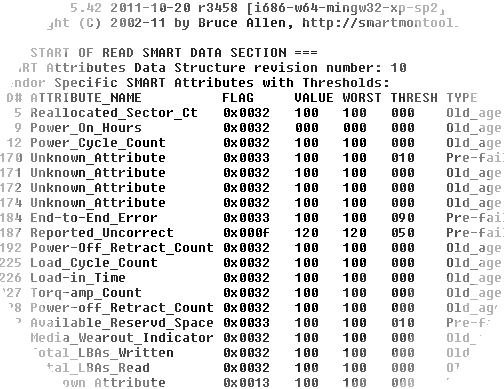 CRITICAL: condition d'erreur critique
CRITICAL: condition d'erreur critique
Remplacer le disque
PRE_FAIL: condition prémonitoire
Faire régulièrement des sauvegardes et penser à acheter un nouveau disque
OLD_AGE: usure normale
Condition normale, tenir les autres paramètres à l'œil.
Il n'est pas possible de "corriger" la condition SMART. C'est le logiciel sur le disque qui indique l'état physique général du disque dur. Si des conditions d'erreur se produisent, il faut remplacer le disque, car ces erreurs iront en s'amplifiant.
- 1 - Raw Read Error Rate
- Cette valeur indique le nombre de fois que l'électronique a du relire des blocs, parce que la lecture n'a pas réussi du premier coup. Ce paramètre est très important et doit attirer l'attention s'il devient brusquement moins bon.
- 2 - Throughput Performance
- Performance générale du disque qui dépend en grande partie de la vitesse d'accès (seek time).
- 3 - Spin up time
- Temps nécessaire pour accélérer les plateaux jusqu'à la vitesse nominale. Cette valeur avait une grande importance à l'époque: il arrivait qu'un disque dur n'arrivait plus à démarrer parce que l'huile des paliers était devenue trop visqueuse (les premiers disques durs avaient même une découpe pour permettre de débloquer le disque avec une clef spéciale). La valeur absolue est le temps en seconde pour atteindre la vitesse de rotation nominale. Cette valeur peut varier du simple au double.
- 4 - Start/stop count
- Nombre de fois que le disque a été mis en route. Le démarrage et le retrait des têtes de la rampe de repos provoque une légère usure.
- 5 - Reallocated sector count
- Nombre de secteurs mis hors fontion. Le firmware va essayer de déplacer les donneées des secteurs défectueux (cette opération est totalement automatique et n'est pas remarquée par le système d'exploitation). C'est pour cela que la plupart des systèmes d'exploitation ne remarquent pas que le disque est défaillant. Chaque disque dispose de secteurs en réserves qui vont être utilisés quand le secteur original est devenu instable.
- 6 - Read Channel Margin
- Réserve de signal à la lecture, correspond au rapport signal/bruit de fond qu'on retrouve en électronique. La piste n'est plus lisible si le signal disparait dans le bruit.
- 7 - Seek Error Rate
- Nombre d'erreurs de positionnement. La tête a été déplacée vers une piste donnée, mais s'est retrouvé sur une piste adjacente. La réduction de la valeur normalisée indique une usure mécanique.
- 8 - Seek Performance
- Vitesse de recherche de la piste correcte. Une réduction de ce paramètre indique ici aussi une usure.
- 9 - Power on hours
- Nombre d'heures en fonctionnement. La réduction de ce paramètre n'indique pas directement une réduction de la fiabilité du disque, il s'agit plutot d'une valeur informative.
- 10 - Spin retry count
- Nombre de temtatives de lancer le moteur. Indique que le disque à tendance à se bloquer à l'arrêt.
- 11 - calibration retry count
- Quand le disque a des difficultés à lire une piste, il effectue un cycle de calibration. Tous les paramètres électroniques sont calculés à nouveau (gain, tracking, kick, etc). Indique que les paramètres de fonctionnement ont changé (changement de température, choc, montage dans un autre ordinateur et passage d'un positionnement vertical à horizontal, par exemple)
- 12 - Power cycle count
- Nombre de fois que le courant a été coupé. Ce paramètres correspond fort au paramètre 4, mais ici on note le nombre de coupures de courant.
- 192 - Power Off retract count
- Les disques actuels n'utilisent plus de zone d'aterrisage des têtes (landing zone), mais une rampe qui tire les têtes des plateaux des disques. Les têtes ne peuvent absolument plus entrer en contact avec la couche magnétique. non seulement elles ne résistent plus au choc, mais de plus les têtes vont immédiatement coller à la surface du disque (stiction).
Il faut absolument éviter ce phénomème, c'est pour cela que les disques utilisent l'énergie cinétique des plateaux en rotation pour retirer le têtes de la surface. Cette opération d'urgence produit un stress qui réduit la fiabilité du disque à long terme.
- 193 - Load/Unload cycle
- Nombre de fois que les têtes ont été parquées en dehors du disque. Cette opération produit une légère usure (moins qu'un retract d'urgence).
- 194 - Temperature
- Température de l'&électronique du disque dur (tempéraure externe). Le paramètre BE indique la température de la circulation d'air à l'intérieur de l'enceinte du disque.
- 194 - Hardware ECC recovered
- Il y a souvent des erreurs de lecture. Celles-ci sont automatiquement corrigées par le système de correction d'erreurs (chaque secteur de 512 bytes dispose de 40 bytes supplémentaires pour corriger les erreurs). Ce compteur compte les erreurs corrigées.
- 196 - Reallocated event count
- Nombre de temtatives de relire un secteur défectueux pour placer les données sur un secteur de réserve. Indique que le disque est défaillant.
- 197 - Current pending sector count
- Nombre de secteurs illisibles en attente d'un déménagement. Les secteurs défectueux sont marqués, mais le déplacement des données n'est effectué que si le secteur peut être lu.
- 198 - Uncorrectable sector count
- Nombre de secteurs en erreur, donc le nombre de secteurs qui ont été déménagés et le nombre de secteurs en attente.
- 199 - Ultra DMA CRC errors
- Nombres d'erreurs entre l'ordinateur et le disque dur. peut être causé par un controller défectueux.
- 200 - Multi-zone error rate
- Il s'agit d'un controle qui est effectué en mode offline (le disque lit tous les secteurs un à un et rapporte l'état de l'analyse).
Les disques SSD (Solid State Disk) génèrent également des paramètres SMART-SSD qui indiquent l'usure des cellules (elles ne peuvent être écrites qu'un nombre limité de fois).
|