-
|
Les disques durs SSD de Intel fournissent un statut SMART. Les différents modèles utilisent tous pratiquement les mêmes codes. La documentation technique en ligne de Intel est bien faite et permet de décoder manuellement les paramètres que l'utilitaire SMART ne connait peut-être pas, tandis que les SSD de Samsung sont fournis avec une documentation (PDF) très complète
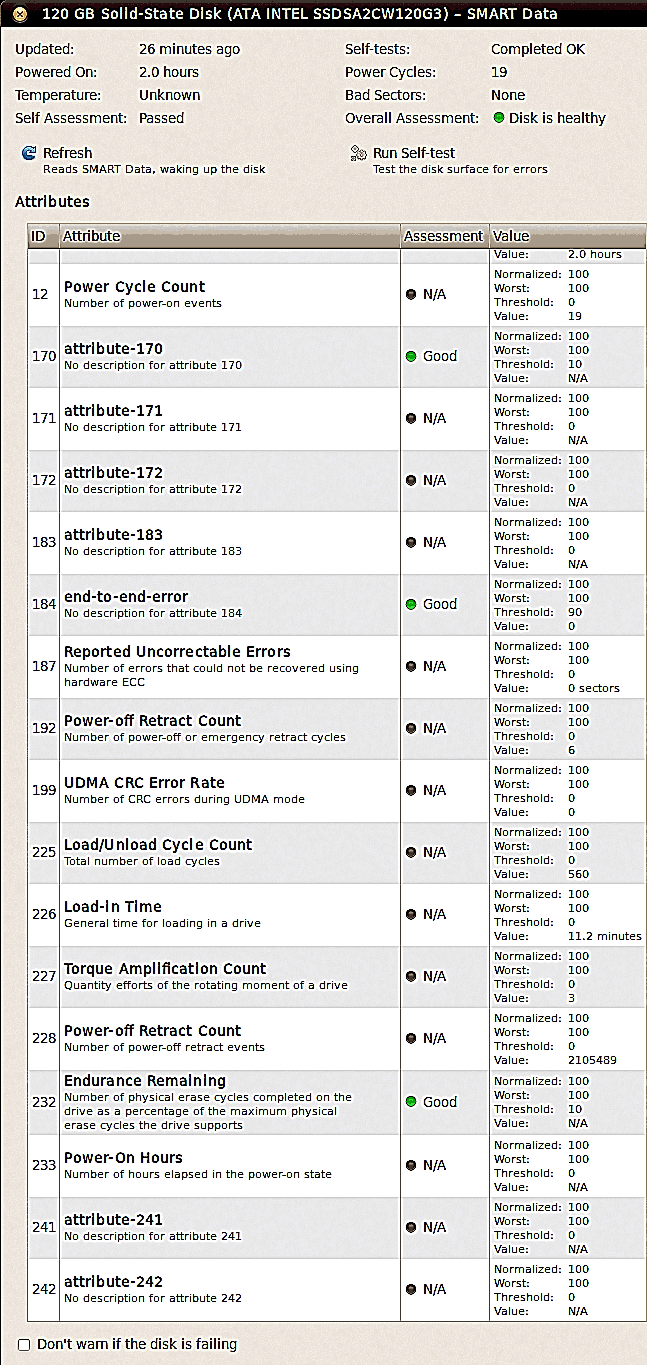
Certains paramètres sont repris en double: selon le type de disque l'un ou l'autre paramètre sera utilisé (il n'y a pas de standardisation, même pas au niveau d'Intel). |

|
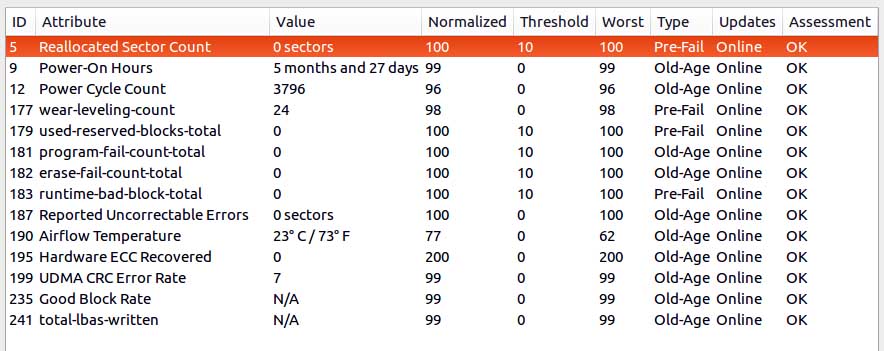
Ce disque indique le nombre d'opérations d'écriture (paramètre 241) et de lecture (paramètre 242), mais également le nombre d'écritures au niveau de la mémoire. Comme vous pouvez le voir, le facteur d'amplification (write amplification) est de pls de 10×, et ce pour un disque qui n'est rempli qu'à 15% environ. On en est à 5TB d'écriture en 2 ans, alors que la durée de vie minimale d'un SSD est de 100TB. Le disque devrait donc tenir le coup plus de 20 ans...
Nous sommes 6 ans plus tard et le disque SSD a maintenant 8 ans de fonctionnement. Les maramètres smart n'ont pas changé (vous pouvez lire en temps réel les paramètres smart de mon serveur). Le paramètre 187 a même augmenté, alors qu'il devrait normalement diminuer avec le nombre d'erreurs qui s'accumulent. Les disques de mémoire moderne du type NVMe (non volatile memory express) n'ont plus de fonction SMART. Ce système a été conçu pour les disques durs avec connecteur ATA et puis SATA. Entretemps nous sommes 30 ans plus tard et on ne vend pratiquement plus d'ordinateurs équipés de disques mécaniques.
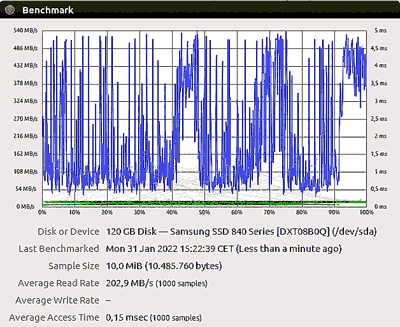
La seule solution c'est de mesurer régulièrement la vitesse des modules de mémoire (bien que cela ne donne pas une certitude que le module est encore bon). Quand un module a besoin de plus de temps pour lire un "secteur", cela veut dire que la mémoire est en fin de vie. Quand le module est défectueux, c'est d'abord l'écriture qui n'est plus possible, mais la lecture devient également plus lente car il faut faire plusieurs tentatives de lecture et utiliser la correction d'erreur. Pour détecter des problèmes, il faut lire suffisamment de blocs, une valeur de 1000 est idéale. La lecture n'use pas la mémoire, contrairement à l'écriture (un bloc peut être écrit au maximum 10.000 fois dans les dernières mémoires triple level cell). |
 Le protocole smart n'a pas vraiment percé pour les disques SSD et c'est surtout la faute des fabricants. Certaines firmes comme Intel transmettent correctement les paramètres, mais le statut n'est jamais adapté avec d'autres fabricants. Les valeurs restent toujours à 100, même pour des disdques qui ont un fonctionnement erratique manifeste. Même un disque qui ne peut pratiquement plus être lu donne toujours un statut OK. C'est probablement pour cela que le protocole smart n'a pas été repris dans la dernière version des modules de mémoire.
Le protocole smart n'a pas vraiment percé pour les disques SSD et c'est surtout la faute des fabricants. Certaines firmes comme Intel transmettent correctement les paramètres, mais le statut n'est jamais adapté avec d'autres fabricants. Les valeurs restent toujours à 100, même pour des disdques qui ont un fonctionnement erratique manifeste. Même un disque qui ne peut pratiquement plus être lu donne toujours un statut OK. C'est probablement pour cela que le protocole smart n'a pas été repris dans la dernière version des modules de mémoire.
Publicités - Reklame